
07.29

【World MR News】統計的ボイチェン研究事情――「#VRSionUp!6」「先端ボイチェン研究」レポートその②
「先端ボイチェン研究」をテーマに、7月16日に開催されたVR研究系ワークショップの「#VRSionUp!6」。本稿ではその中から、東京大学の高道慎之介氏によるセッション「統計的ボイチェン研究事情」をピックアップしてお届けする。

▲高道慎之介氏。
■人と計算機が音声でコミュニケーションを出来る社会を目指す
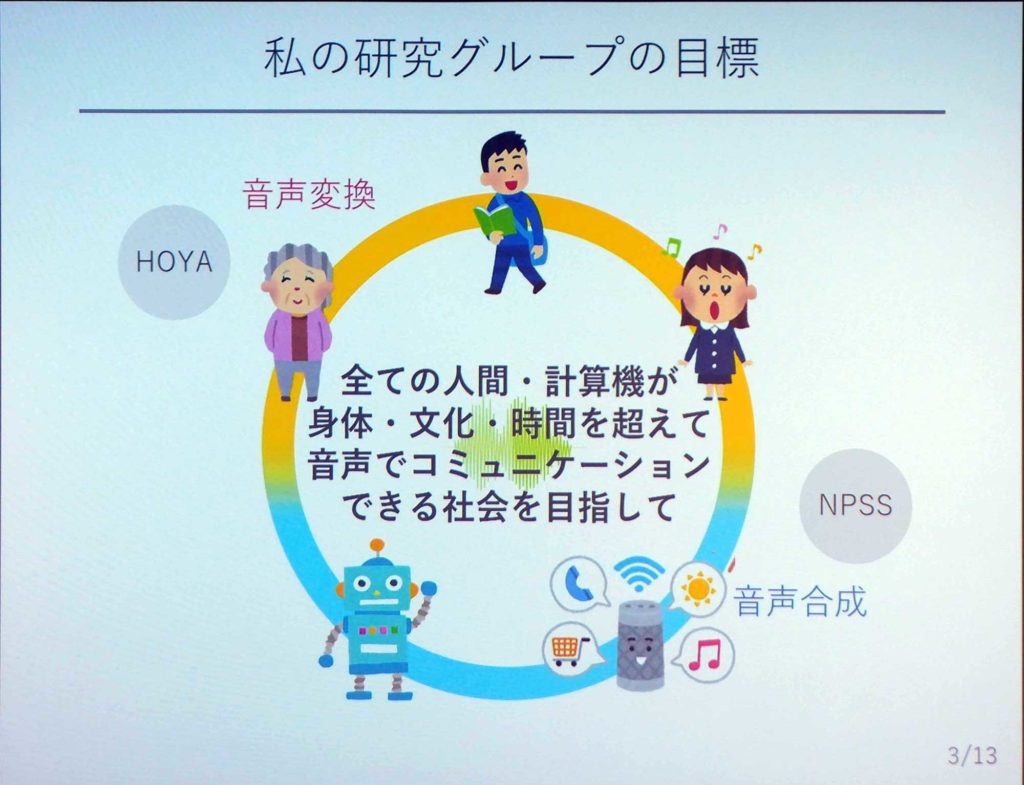
「統計的ボイチェン」とは、音声の特徴と機械学習(ディープラーニングなど)を使って構築するボイスチェンジャーのことをさしている。2019年の時点で、人と人が声で出来ることが異なる。その理由は身体が異なるから。同様に、人とコンピューター(AI)が声で出来ることも異なる。
高道氏の研究グループは、この世に存在しているあらゆる人とモノ(コンピューター)が、身体の違いや文化、時間の違いを超えて、音声でコミュニケーションを出来る社会を目指している。
それを実現するために、ふたつの技術を使用している。ひとつは、「音声合成」だ。こちらはコンピューターが話すための技術だ。もうひとつはボイスチェンジャーで、こちらは専門用語では「音声変換」と呼ばれる技術である。これらを使い、人とコンピューターの境目を無くしていこうとしている。
■ディープラーニングで声を学習してリアルタイムにボイスチェンジ
今回のセッションは、大きく分けて4つのテーマがある。ひとつ目は、特定の他者にリアルタイムでなりきるボイスチェンジャーだ。ふたつ目は、他人との「声のつながり」を見つけるボイスグラフ。3つ目は、「声の誤り」を学習・付与するボイスエフェクタ、4つ目が、次世代ボイスチェンジャーに向けた試みである。
まずは、リアルタイムボイスチェンジャー(話者変換)の話から。
上記の動画は、実在している人の声に高道氏の声をリアルタイムに変換したときのものだ。普通のノートPCで動作させることができ、レイテンシーは50msとほとんどラグを感じないレベルである。
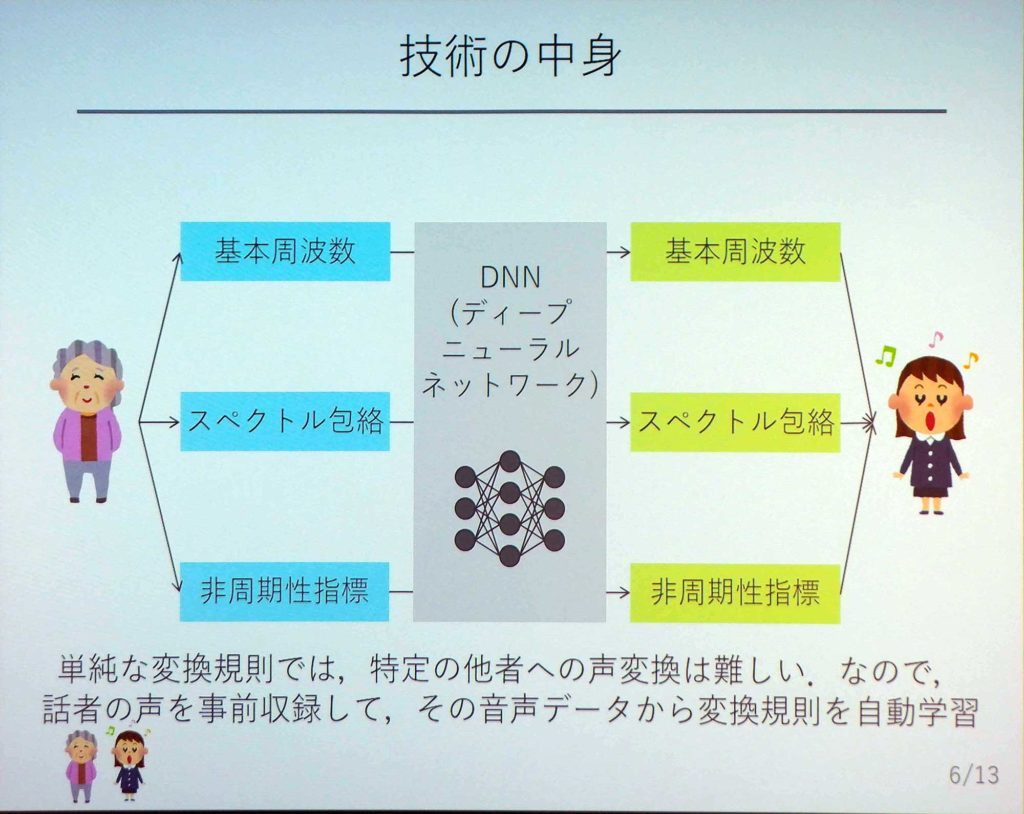
こちらは、森勢将雅氏の開発した『WORLD』を使用しており、入力側の人の声を「基本周波数」「スペクトル包絡」「非周期性指標」の3つに分ける。それを、何かしらの変換規則を使って特徴量を変化させている。
特定の個人から別の特定の個人に変える場合、簡単に変換規則を決めることができない。そこで、両者の声を事前に集めておき、その音声データから変換の規則を学習させていく。こちらでは、その変換規則を学習しているのはDNN(ディープニューラルネットワーク)だ。先ほどの動画のデモは、だいたい20分ぐらい学習させているそうだ。
■ボイスグラフで声の関係性を分析
続いて、他人との「声のつながり」を見つけるボイスグラフの話だ。フェイスブックやツイッターなどのSNSで新しいフォロワーが増えたときに、「この人誰だろう?」と見に行って「○○さんにフォローされているな」と言う感じで、フォロワーの関係で人間関係を探っていくことがある。
高道氏は、そうした関係性は声でもできると考えている。そこで、その関係性のグラフを作っている。まず、ふたつの音声データを4000人に聞いてもらい、「ふたりの声はどれぐらい似ているか」というアンケートを実施した。

「-3」は全然似ていない、「+3」はすごく似ているというアンケートをひたすら繰り返した結果、下記のようなグラフが出来上がった。
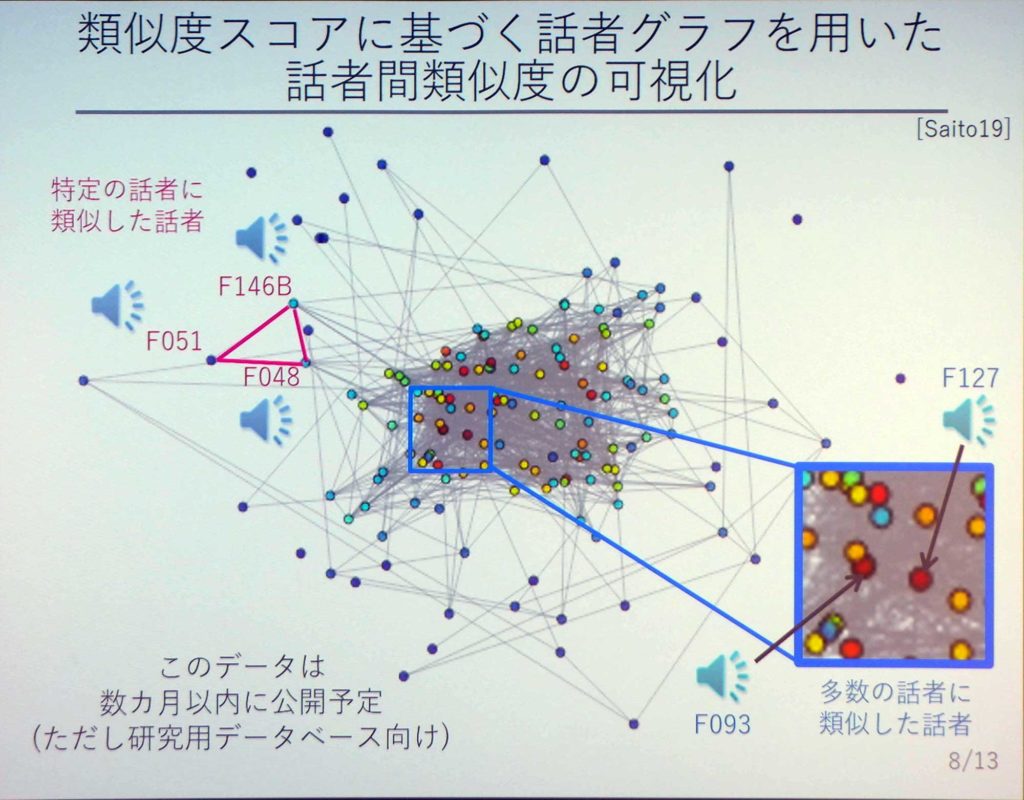
ひとつひとつの点はある人を表しており、線で繋がっている。その線で繋がった部分は、人が聞いて似ている声だと感じたものを表している。中でも、グラフの中央に集中しているような、いろんな人と繋がっている人の声は、言い換えると特徴のない平凡な声だ。このようなことも、このグラフからわかるようになっているのである。
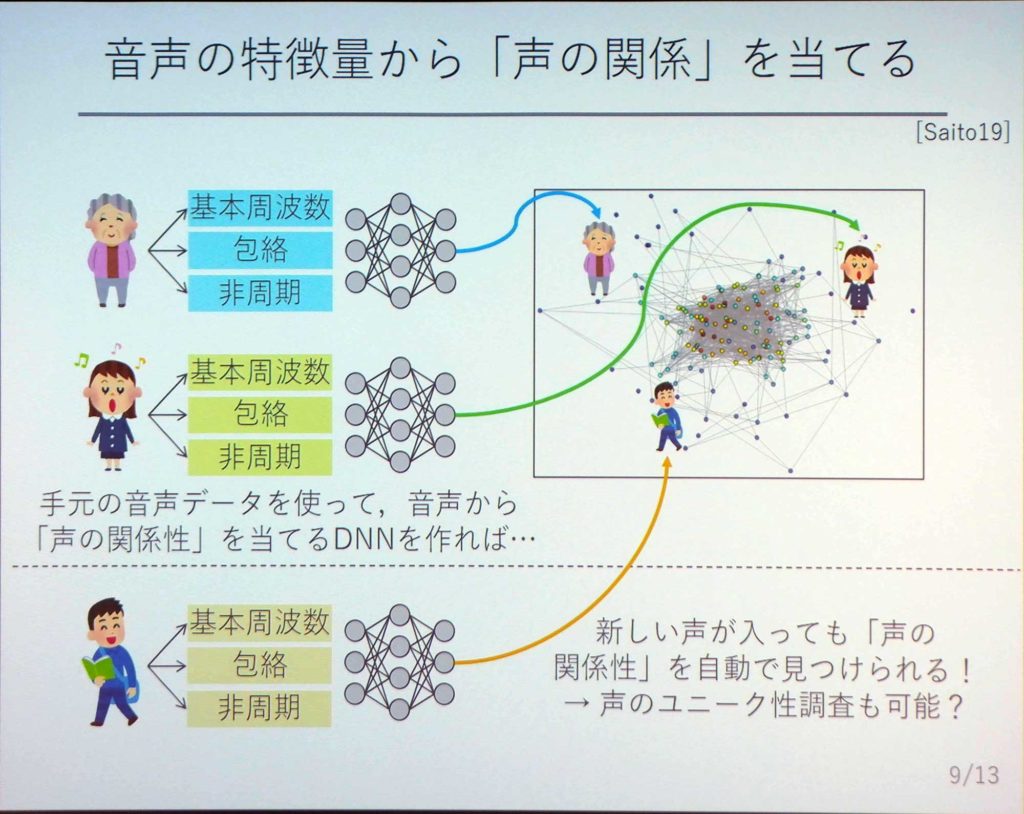
たとえば『WORLD』を使って、おばあちゃんの声と女の子の声を獲得しておく。そのあと、DNNを使い声の関係性を学習していく。こうしたものを1度作っておくと、新しい人が入ってきたときでも関係性がわかるようになるのだ。
また、ボイスチェンジャーを使って声を入力したときに、その声が他の人と被っているかどうかといったことも自動で分析することが可能になる。ボイスチェンジャーを使った結果、グラフの真ん中あたりになるといろんな人と被ってしまい、個性がない声になっていることがわかる。それとは逆に、誰とも繋がっていないときは誰にも真似が出来ないユニークな声だと分析することができるのである。
■人間の間違い方を学習
続いてはボイスエフェクタの話に移る。高道氏が最近目標にしているのは、「人間の間違い方を学習」することだという。人間が起こす間違いはいろいろと面白い。例えばセリフを噛んだときに笑いが起こって、コミュニケーションが生まれるということがある。また、体調を崩していつもと違う声になり、偶然優れた話し方や歌い方を見つけるといったこともあるかもしれない。このように、人間の間違いは新たな創造性を生むのである。
そこで高道氏は、その人間の間違いをコンピューターが覚えることができるのかということを実装している。
ボーカルの録音に「ダブル・トラッキング」と呼ばれる手法が使われることがある。ビートルズなどが採用していたことでも有名な録音方法だが、ボーカルが同じフレーズを2回歌い重ねて録音する。そのときの微妙な声のずれにより、サウンドに厚みが増すのだ。これは人間が間違えることから実現しているとも言える。
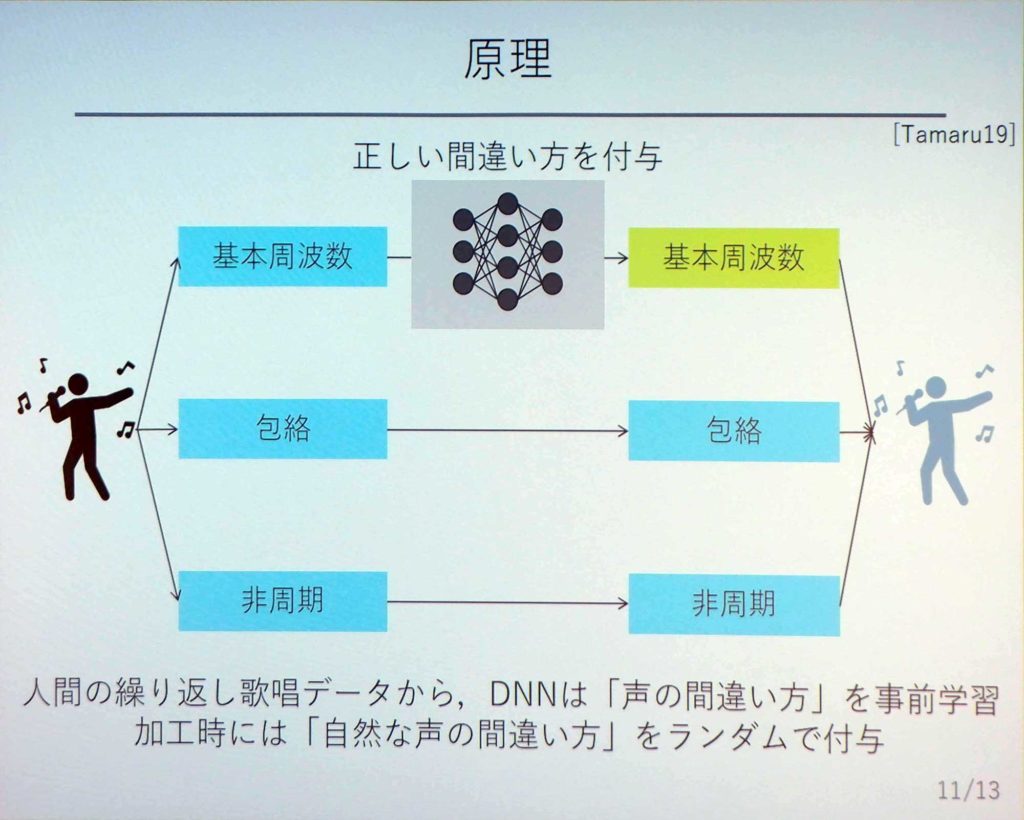
その間違えを機械で学習させようとしてみた。ある人が1度だけ歌声を録音し、それを元に「NDT(ニュートラル・ダブル・トラック)」というものを介して人工的に間違えを再現する。その間違った声を、元の声に足すという仕組みだ。この技術を使うことで、1度しか歌っていなくとも重ね録りしたときと同じような効果を得ることができる。
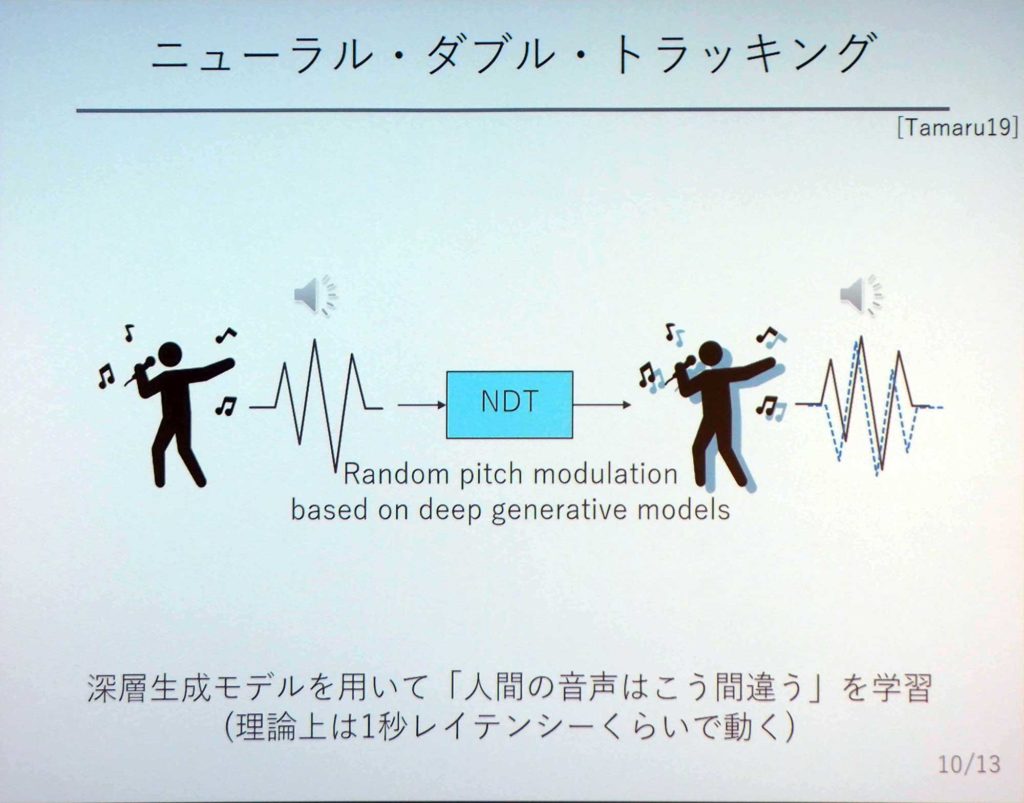
入力された声に対して、「基本周波数」「包絡」「非周期」の3つに分ける。その中の音高に相当する「基本周波数」の部分だけ、人工的に間違いを付与する。そこで、間違い方を学習するニューラルネットワークを作っておく。そうしれ出来上がった間違った歌声を重ねることで、自然で厚みのある歌声になるのだ。
■ストレスのないボイスチェンジャー作りのプロジェクトもスタート
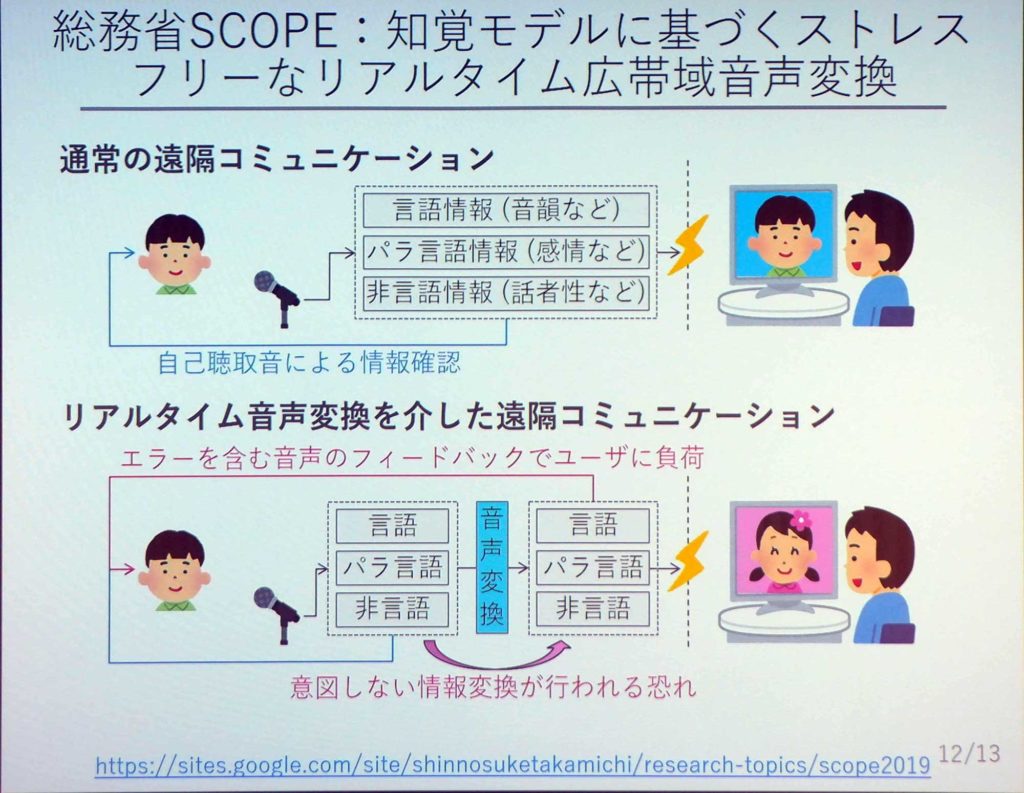
高道氏は現在、このボイスチェンジャーを使った総務省の『SCOPE』という、大型の研究を進めている。これは、ボイスチェンジャーを使い、心地よい声を作るといった内容のものだ。
たとえば配信を地声でやるときは、マイクで話した声が相手に伝わる。そこでボイスチェンジャーを使う場合、何らかの変換された声が相手に伝わる。しかし、このボイスチェンジャーは自分の思っているとおりに出るとは限らない。そうなると、人はストレスを感じてしまう。
そこで、使っている人がストレスを感じず心地よく使えるボイスチェンジャー作りをプロジェクトとして進めているそうだ。
■Shinnosuke Takamichi (高道 慎之介) – SCOPE2019
https://sites.google.com/site/shinnosuketakamichi/research-topics/scope2019
現在のボイスチェンジャーは、高品質化や高速が研究のメインになっている。これからどんなところを目指すのかというと、ひとつは「ヒトとコトをどこまで分離できるか」ということであるという。今は身体から出せる声はある程度決まっている。その身体の制約をどれぐらい外すことができるかというものだ。
もうひとつは、リアルタイムボイスチェンジを使って自分の声を変化させたときに、話し手の人格が変わってくるのではないかと、高道氏は考えている。
こうしたボイスチェンジャーの研究をしていると、声優の仕事を奪うことになるのではないかという意見をよく耳にするという。しかし、高道氏は、「声優の仕事自体を奪うことはないが、今とは声優のあり方が変わってくる」と考えているそうだ。
Photo&Words 高島おしゃむ
コンピュータホビー雑誌「ログイン」の編集者を経て、1999年よりフリーに。
雑誌の執筆や、ドリームキャスト用のポータルサイト「イサオ マガジン トゥデイ」の
企画・運用等に携わる。
その後、ドワンゴでモバイルサイトの企画・運営等を経て、2014年より再びフリーで活動中。