
07.29

【World MR News】圧縮から声を変化する技術へと進化した「Vocoder」の歴史――「#VRSionUp!6」「先端ボイチェン研究」レポートその①
GREE VR Studio Labは、7月16日に「VRを通したイノベーションの発掘」をテーマにしたVR研究系ワークショップ「#VRSionUp!6」を開催した。昨年12月12日に開催された「VRSionUp! #0」よりスタートした本イベント。通算7回目となるが、今回でひとまずこのシリーズは終了となる。そのラストに選ばれたテーマは「先端ボイチェン研究」だ。
ここ最近のVTuberブームの影響もあってか、自分の声を別人のように変えるテクノロジーも注目を集めている。ということもあってか、今回のイベントでは最初の50分を使い、ボイストレーナーの吉岡研一郎氏指導で、参加者全員がボイストレーニングに挑戦するというコーナーも用意されていた。
本稿ではその中から、明治大学 総号数理学部最先端メディアサイエンス学科 森勢将雅氏によるセッションの模様をお届けする。

▲本イベントを主催するGREE VR Studio Labの白井暁彦氏。

▲ボイストレーナーの吉岡研一郎氏。トレーニング中、参加者の声も出し方もみるみる変わっていった。
■アルティメット☆Vocoder
ボイストレーニング講座に続き、明治大学の森勢将雅氏からは、「アルティメット☆Vocoder」というテーマで、声を変えることができる「Vocoder(ボコーダー)」の原理についてわかりやすく紹介が行われた。

▲森勢将雅氏。
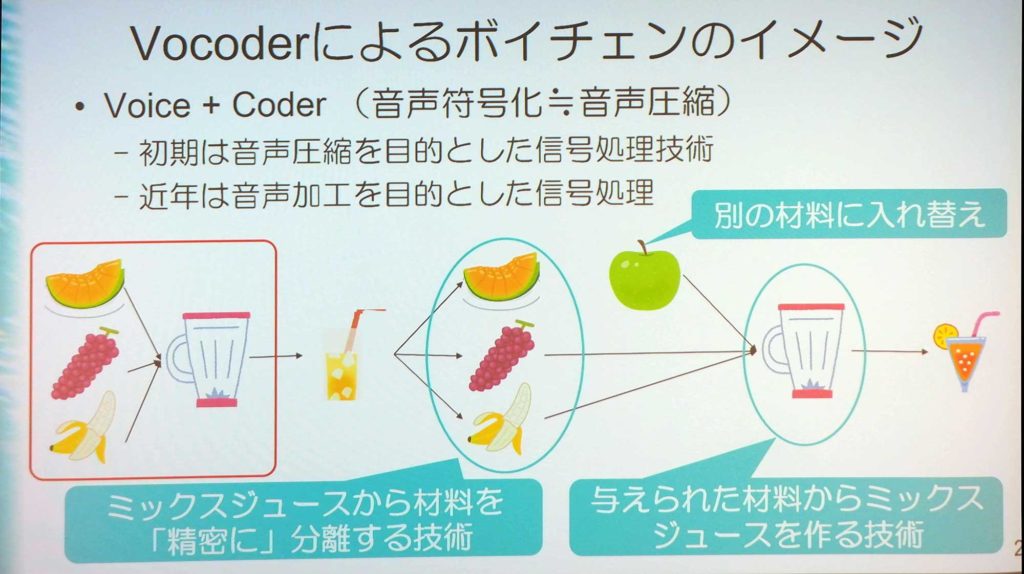
「Vocoder」という言葉を聞いたことがある人はどれぐらいいるだろうか? この語源は「Voice」と「Coder」を合わせたもので、声を符号化するというところから名付けられている。
「Vocoder」は、音声通信でいかに音を圧縮するかというのを目的に生まれたものだ。それ以降、高さと音色に分けてそれぞれを効率よく表現するという研究が行われてきた。しかし、最近はインターネットの速度も上がり、以前は音声の波形をそのまま送るのが難しかったのが今では問題なく送れる時代になってきている。そこで、1990年代後半からよりクォリティを重視する方向に変化している。そこから様々なツールが生まれ、現在に至るといった感じだ。
声は高さ、音色など様々な情報で成り立っている。人間の発声は、マイクで音の波形でしか録音することができない。これは、複数のフルーツが混ざったミックスジュースを観測しているようなものである。
「Vocoder」は、例えるならミックスジュースから元の原材料を分離するような作業を行うようなものだ。混ざっているものから分離するのは難しく、その研究が行われてきている。音を分離することができるようになると、もう1度混ぜることも可能だ。そのときに、別の材料に置き換えて作ることもできる。
ボイスチェンジャーで別人の声にしたいときは、この材料を別のものに入れ替えることを実現することができる。元々は圧縮から始まったが、現在は以下に声を柔軟に変えるかといった技術に変わってきているのである。
森勢氏が現在作っている『WORLD』と呼ばれる「Vocoder」は、声の高さに関するものを「基本周波数」、音色に関するものを「スペクトル包絡」、声がどれぐらいかすれているかを表す「非周期性指標」の3つの要素を抽出し、再合成することができる。
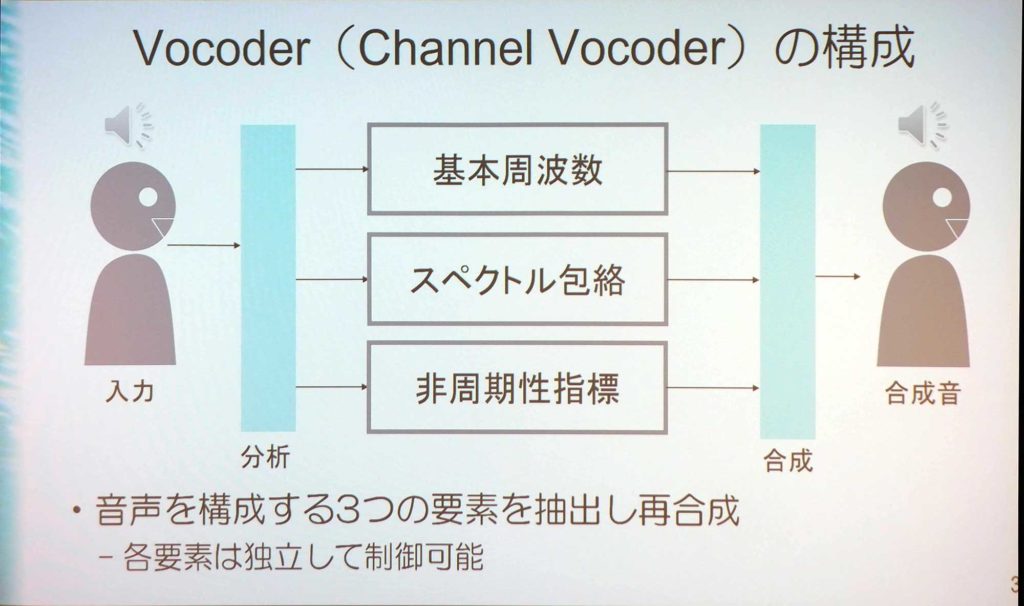
会場内のデモで流された音声では、元の声と合成した音声の差がほとんどわからなかった。こちらは、高さと音色だけから作っており、元の波形は使用していない。声の高さは、声帯の振動する周期だ。音色は、喉から出てきたものは声の種で、そこに口の形を変えることで決定される。このふたつの情報を、混ざり合った波形から取り出しているのだ。 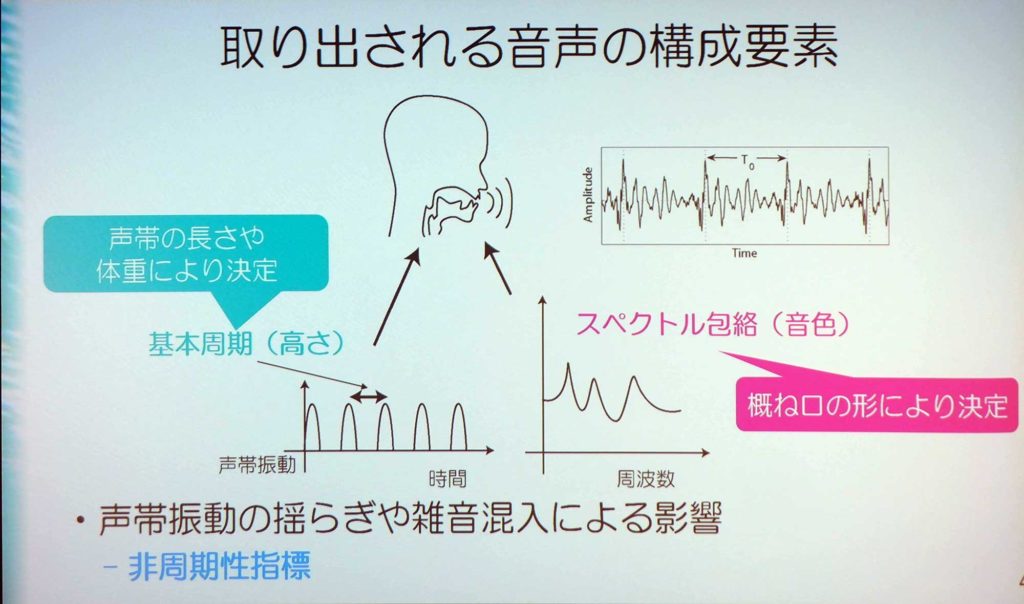
「Vocoder」の歴史は、1939年の『voder』から始まり、1960年代には、今でも使われている最先端の核となる考え方が出来た。そこから、圧縮するという考え方から進化している。その当時は音質も悪く、ロボット声と呼ばれることも多かった。
1997年に、初めて人間の声と遜色ない品質を持つ「Vocoder」の『STRAIGHT』が誕生している。しかし、音声圧縮をするというコンセプトからは大きく外れており、元の波形からサイズが50倍にも膨れてしまった。
2000年代前半に使われていたコンピューターで、3秒ぐらいの音声を分析するのに1分ほど掛かってしまい、サイズが大きすぎてメモリーも溢れてしまう状況だった。そこから、2010年代からはかなり進化を遂げており、『STRAIGHT』よりも品質も良くなり、符号化効率にも優れた方法が登場してきている。これにより、応用範囲も広がってきているのだ。

■ボイスチェンジャーには基盤技術で高さと音色に分離する「Vocoder」がある
男性の声を高さと音色で分離すると「あいうえお」と話したときに、「あ」~「い」にかけては上がっていき、「う」~「お」にかけて下がっていく。これを合成しても同じ声になるが、音色の情報は残しておき高さをフラットにすると、ロボットのような声に変換することができる。
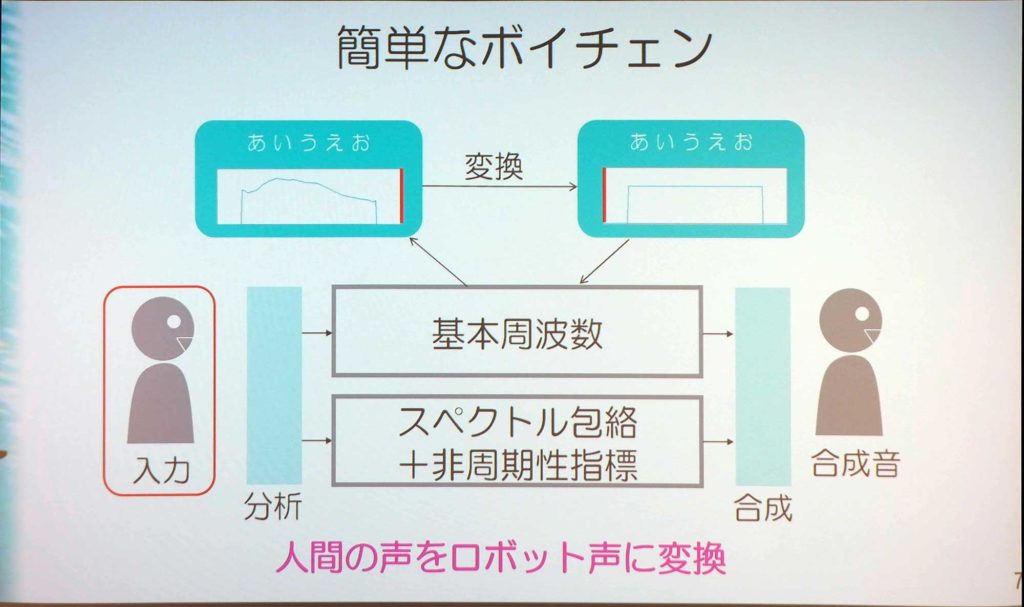
そこで、10年程前にカラオケでプロの歌い方で素人の歌い方をうまくできないかというデモを作っている。
このように、高さを変えるだけでもある程度上手くいく。ボイスチェンジャーというと別人の声に変えるというイメージを持っている人も多いが、こちらもボイスチェンジャーのひとつである。ここでポイントとなるのは、基盤技術として高さと音色に分離する「Vocoder」があるということだ。
■声の高さを変えるだけでは男性の声は女性の声にならない
男性の声を女性の声のように変える場合、ただ声を高くしても高く話しているようにしか聞こえない。女性に変えるには、身長を小さくする必要があるのだ。男性と女性では、女性は身長が低い傾向にある。顔が小さく、声帯や声道の長さも少し短い。
そのため、音色の変換をするときに声道を縮めるような変換を入れる必要があるのだ。これを、「声道長変換」と呼んでいる。高さを変えつつ、声道を短く変換することで、性別がちょうどいい感じで変わるのだ。
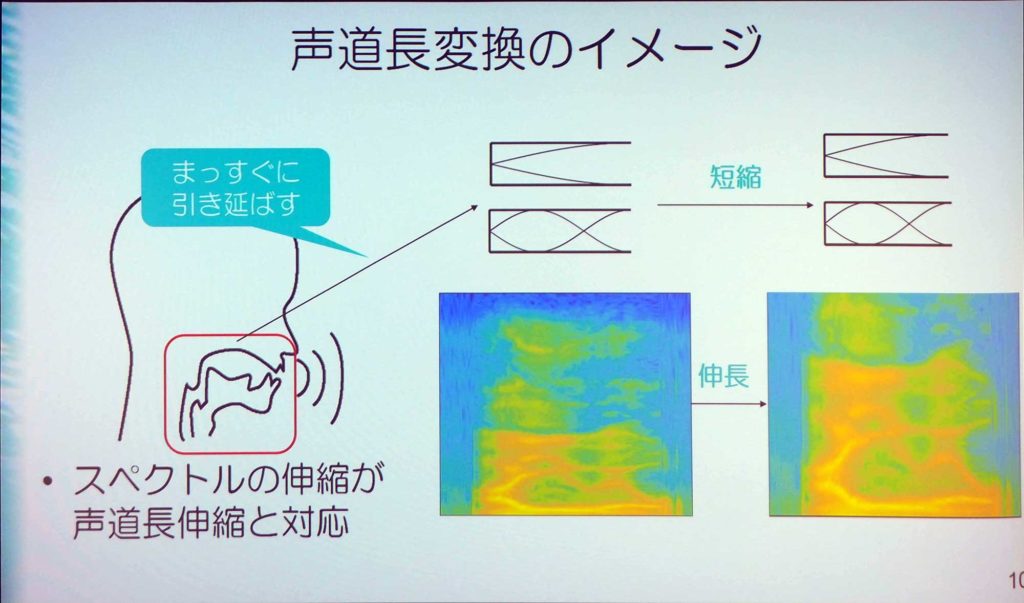
しかし、この男性の声を女性の声に変換するときに上手くいかないことがある。男性は声道長が長く声が低い、女性は声道長が短く声が高い。そのため声の性別を変更するのは、高さと声道長に特定の変化を与えると解釈することができる。
たまたま男性エリアから女性エリアにいく人は、ボイスチェンジャーとの相性がいいということになる。だが、男性エリアからやや外れている人は、謎のエリアに行ってしまう。そうした人たちは、女性エリアに行くような別の変化のさせ方を考える必要があるのだ。
元々自分の声がどのエリアか知った上で、適切なエリアに持って行くということを考えるのが、性別変換の大きなコツとなるのである。
また、特定の誰かを目指す場合は難しい。目的地への変換ルールは、男性それぞれのしゃべり方によってもまったく異なる。そのため、その人にあった変換関数を作る必要があるのだ。また自分のエリアの位置も知っておく必要がある。その上で、変換を行うのだ。
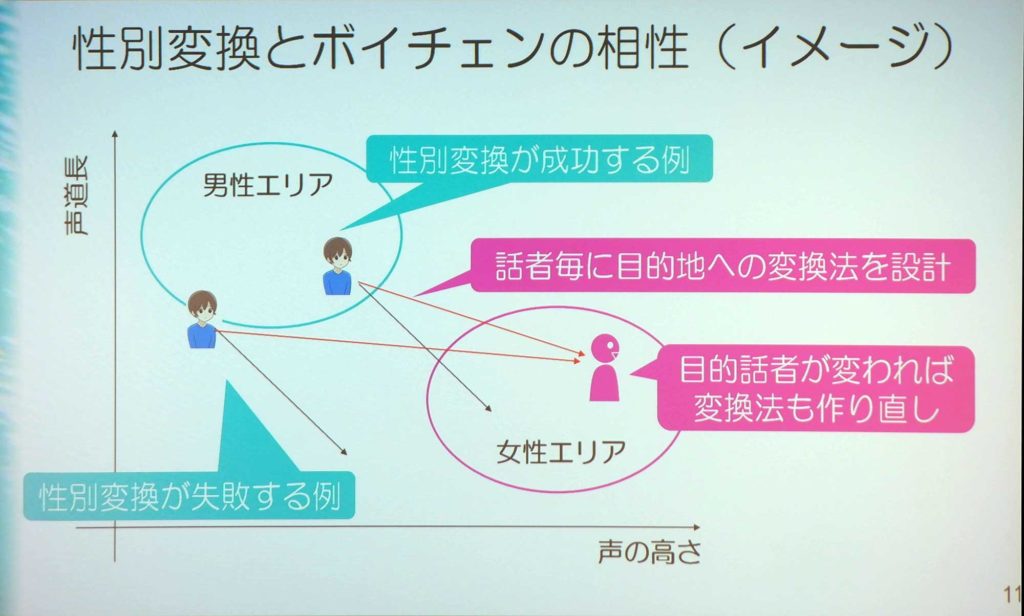
ボイスチェンジャーでは、話し方が重要だ。性別を変換する場合は話し方も意識する必要がある。高さと声道長を変えるだけでは、話し方のイントネーションは変わらない。そのため、男性がそのまま女性エリアの声に変換すると子供っぽい声になる。逆に、女性が男性の声に変換すると、丁寧な話し方の男性になる傾向が強いという。
男性が女性の声になる場合、話す側が女性らしさを意識することで、出てくる変換結果の声も女性っぽくなるのだ。
Photo&Words 高島おしゃむ
コンピュータホビー雑誌「ログイン」の編集者を経て、1999年よりフリーに。
雑誌の執筆や、ドリームキャスト用のポータルサイト「イサオ マガジン トゥデイ」の
企画・運用等に携わる。
その後、ドワンゴでモバイルサイトの企画・運営等を経て、2014年より再びフリーで活動中。