
06.21

【World MR News】「de:code 2019」に参加できなかった人のための特別イベント「de:code 2019 振り返り Night!」が開催
5月29日と30日の2日間開催された、年に1度のエンジニア向けの祭典「de:code 2019」。様々な事情で本イベントに参加できなかった人も多かったと思うが、そうした人たちのために、日本マイクロソフトが6月10日に「de:code 2019 振り返り Night! 」を開催した。
当日は、クラウドからデータ・プラットフォーム、AI、IoTの4分野に分けてセッションが行われ、実際に「de:code 2019」で実施された数多くのトラックの中からポイントを厳選して、初心者でもわかりやすい形で紹介が行われた。本稿ではその中から、AIに関するセッションをピックアップしてご紹介していく。
▲当日の模様はこちらの動画でも閲覧可能だ。
■マイクロソフトのツールによってデベロッパーが出来ることが広がっている
今回AIのセッションを担当したのは、日本マイクロソフト コマーシャルソフトウェアエンジニアリング本部 プリンシパル ソフトウェア デベロップメント エンジニアの畠山大有氏だ。

▲畠山大有氏。
今回の「de:code」を経て、マイクロソフトのツールもかなり進化してきたと畑山氏。中でも「Cognitive Service」の「Customize」シリーズがかなり良くなってきている。それに加えて、その中にはディープラーニング界隈でよく使われている「Transfer Learning」の最新版が採用されている。
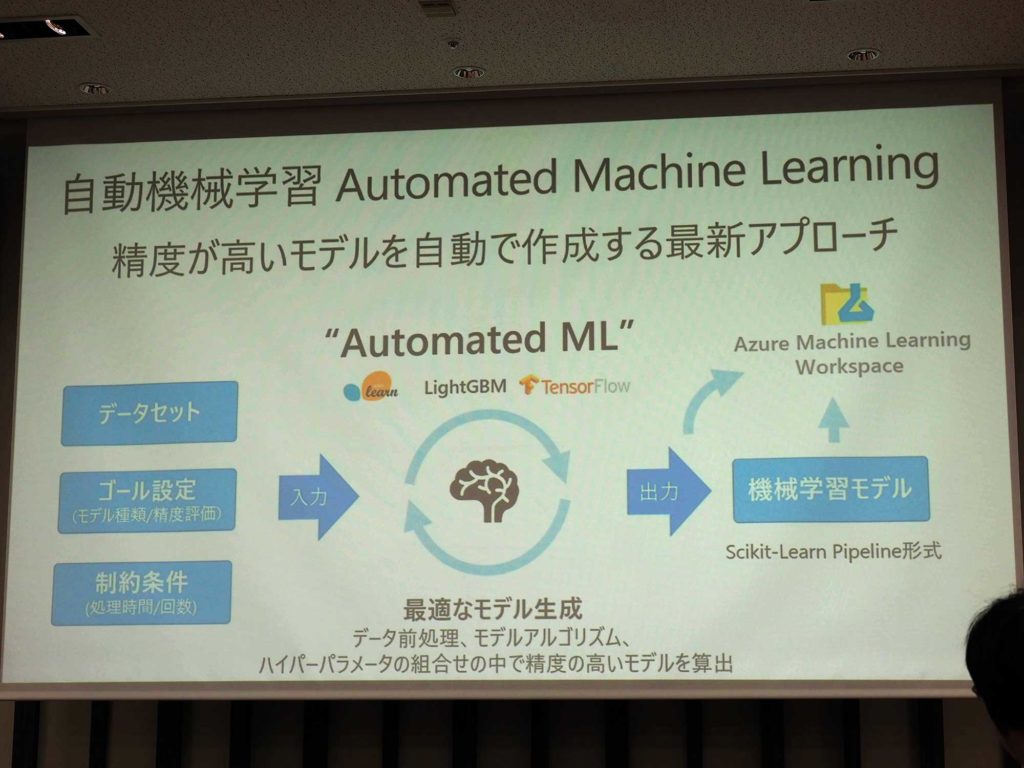
「Azure Machine Learning」の中に入っている「Automated ML」も相当良くなっているという。そのため、学習をさせる、モデルを作るといった選択が広がってきているのだ。
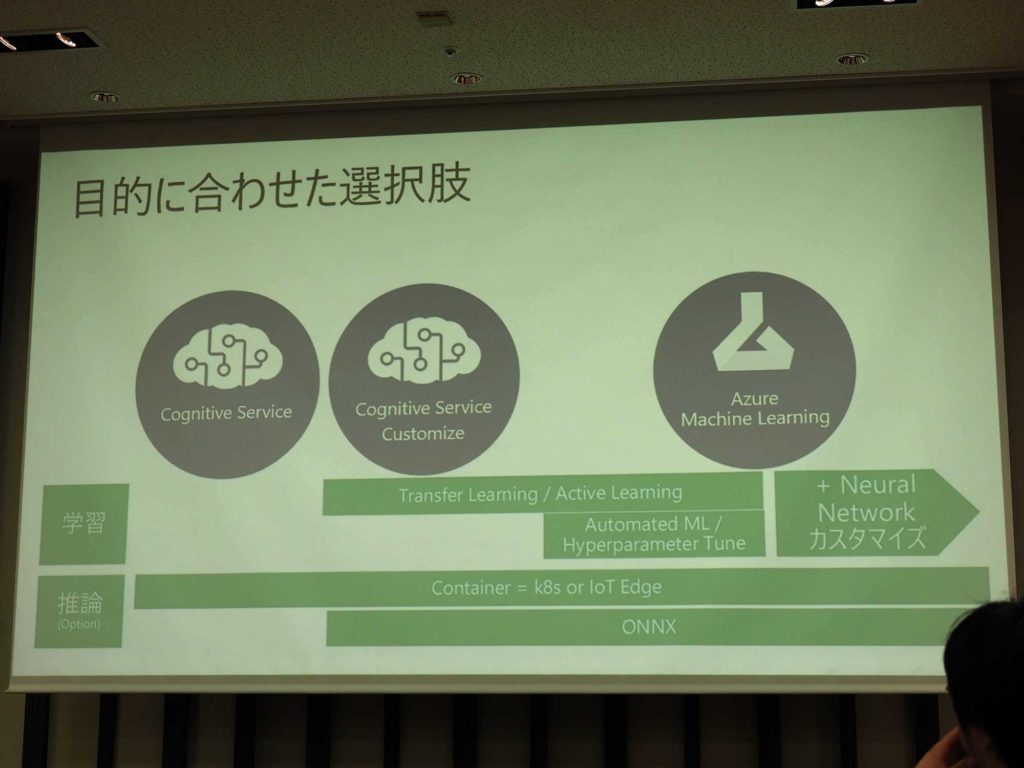
すべてのサービスで他社と違うのは、100パーセントコンテナ対応しているところだ。「Cognitive Service」の様々なエンジンが、KubernetesやAzure Functionsの中、他社のクラウドなどで動かすことができる。しかもオンプレミスで動かすことができるのだ。畑山氏によると、マイクロソフトが提供するツールによってデベロッパーが出来ることが拡がっているのだという。
■”Everday AI”時代の人工知能使いこなし
AI01のセッションで行われたのが、「”Everday AI”時代の人工知能使いこなし」だ。「Cognitive Service」には様々な統廃合があった。新しく「Decision」というカテゴラリーが作られ、この中に、外に出してはいけない写真などを判定する「Content Moderator」に加えて、異常検知をする「Anomaly Detector」などが入ってきた。しかし、まだ本番で使うには相当辛い状態であるため、出てきたことを認識する程度にしておいたほうがよい。また、「Personalizer」も追加されている。

ここでひとつだけデモで紹介されたのが、「Form Recognizer」だ。これは、簡単にいうとレシートなどをスキャンして文字として返すサービスである。ちなみにまだ日本語に対応していないため、日本語のレシートには使えない。
OCRでレシートの文字を読み取ったものが、店名やアドレスなどを判断して、データに意味を付けて取り込むことができるのである。
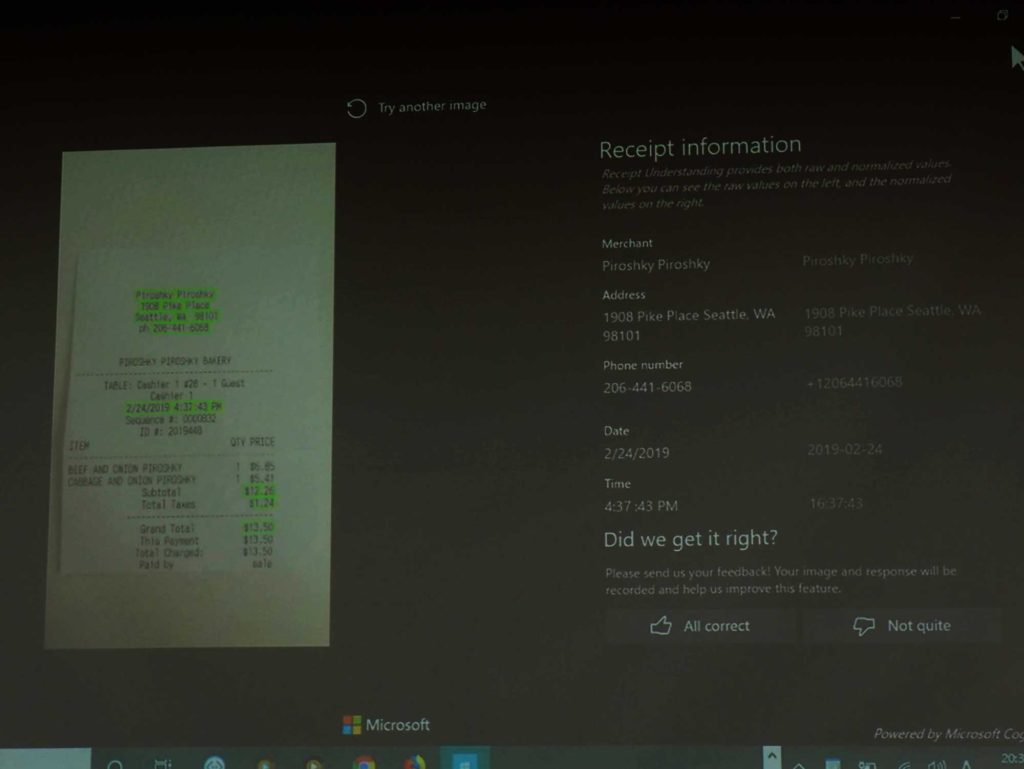
▲かなり便利そうだが、早く日本語化されることが待ち望まれる機能だ。
■Azure Machine Learning service Deep Dive
AI03のセッションで行われたのが、「Azure Machine Learning service Deep Dive」だ。プログラマーが機械学習を使いやすく感じるのは、「Automated Machine Lerning」という機能につきると、畠山氏はいう。
「ビジュアル インターフェイスを使用してモデルを作成する(プレビュー)」というボタンがあり、それを押すと初めて機械学習する人向けの機能が利用できる。トレーニング時に、データを持ってきてアルゴリズムを選択するのだが、細かいデータを入力する必要があり、なかなか決めるのが難しい。それをスパッとやってくれるのが、「新しい自動機械学習モデルを作成する(プレビュー)」だ。
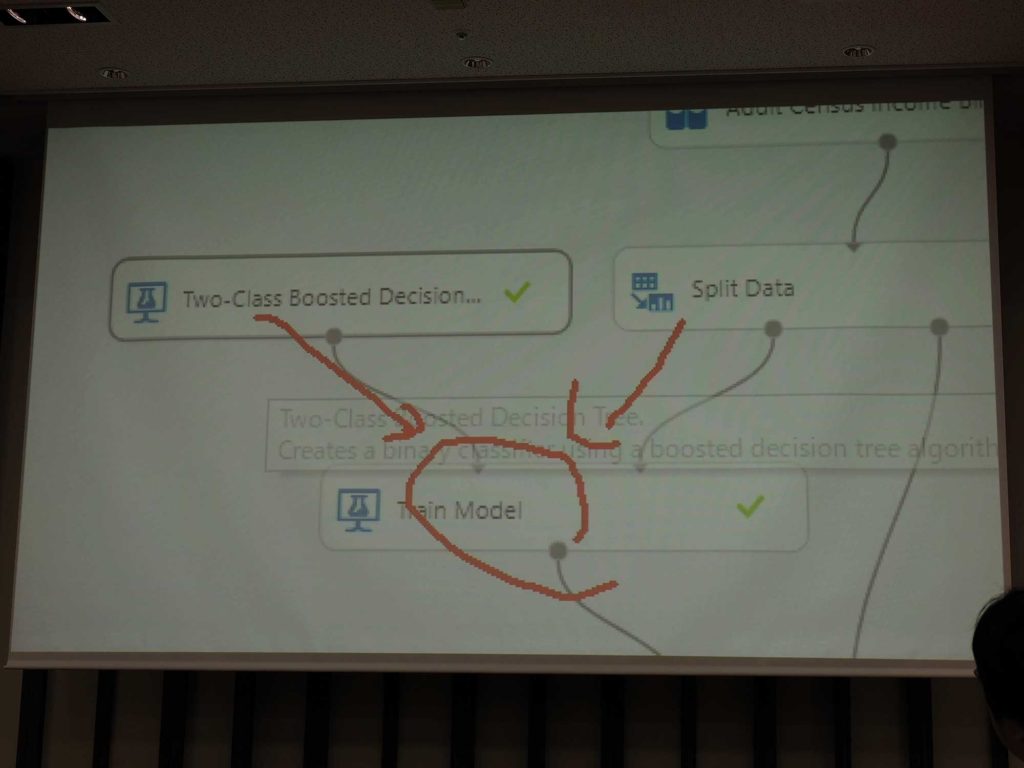
▲「ビジュアル インターフェイスを使用してモデルを作成する(プレビュー)」を押した後に出てくる画面。アルゴリズムを選択していく必要がある。
「Automated Machine Lerning」は、普通の値系を自動的に処理してアルゴリズムを選んでくれ、ディープラーニングで行いたい処理も「Hyperparameter Tuning」という機能があり、別で行える。そのため、簡単なコードを書くだけで最初のプロトタイプのフェーズが終わってしまう可能性が高いのである。
■機械学習のためのデータ加工
ツールに続きノウハウとして、AI08のセッション「機械学習のためのデータ加工~特徴量の見つけ方と作り方」の紹介が行われた。
機械学習のプロジェクトにおいて、データを作らないということはない。作るデータは、ビジネスの目的によって変わってくる。例えば営業日などは、ビジネスごとに変わる。それに加えて、気象データなども必要になってくる場合もある。
こちらでは、ユーザーがデータを持っていないときにどうしたかというケースを3つ紹介している。ひとつ目は、ユーザー評価のないレコメンドモデルだ。ある客がこの店に行くのではないかという、レコメンド機能を作りたいときがある。これには、ユーザーがどう評価したのかというデータがないと、作ることができない。
ユーザーの評価データがないとなると、普通はできないと答える。しかし、そこでデータがない部分に関して利用回数などが使えないか検討した。ユーザーの利用回数をマトリックスに埋めていった。また、基礎集計を見てほとんどの人が1回しか利用していないことがわかった。
利用回数は1~54回までバラバラで、1~54までの分類が存在するということになる。目的は飲食店のリピーターを探したいということだったため、0回と1回、2回以上に評価データを分類。ここで見たかったのはリピーターであるため、2回以上が該当データとなる。それによると、Nullも埋めることができ評価マトリックスを完成させている。
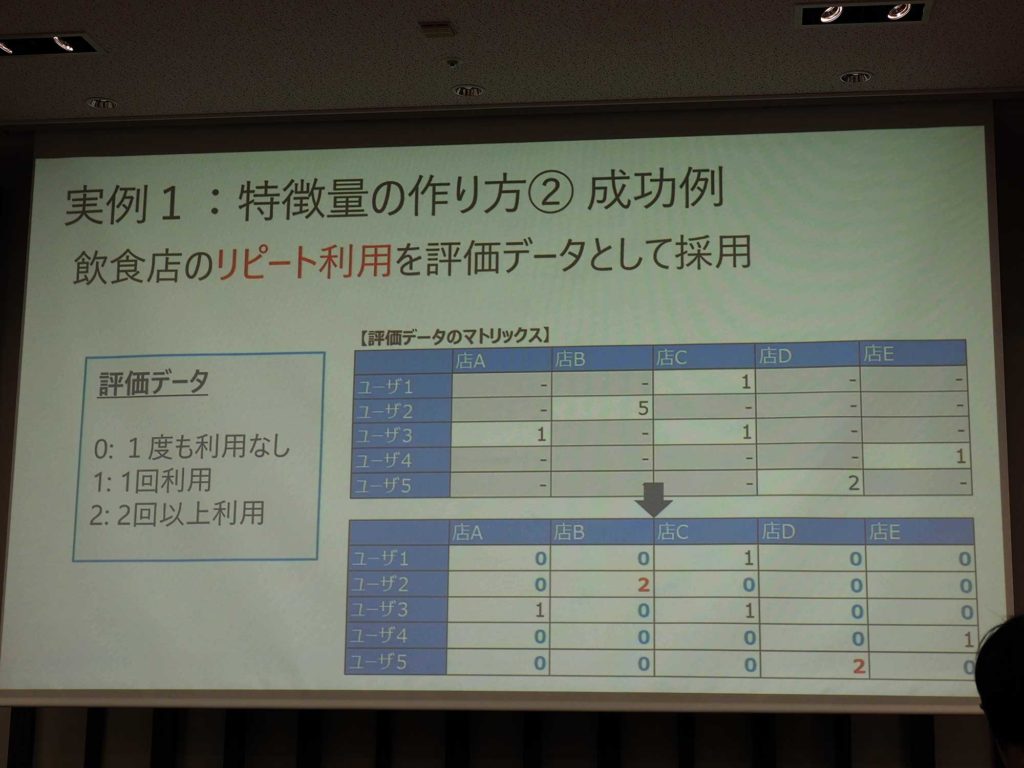
▲元々データが無いときでも、目的に応じて数字を加工して作ることが出来る場合もある。
■あなたがコルタナさんに『ラーメン』と訪ねたとき、それはコルタナさんに何を求めていますか?
ふたつ目は、AI04のセッションで行われた「あなたがコルタナさんに『ラーメン』と訪ねたとき、それはコルタナさんに何を求めていますか?」だ。タイトルからは想像が付かないが、これはチャットボットで「ラーメン」とだけ話しかけたときに、コルタナは検索を行うのだが、それがこちらのセッションのテーマである。

何かを検索するときに、ユーザーは多くの情報を入れない。それでは、検索エンジンを作る側としては情報を出すことができない。検索意図を考えたときに、今いる場所や一緒に来た人の人数などの情報量が多ければ、検索することができる。そこで、何をしたいのか推測してあげることになる。それを4つのイベントに絞って、解析する。

言葉の繋がりはグラフ構造になっており、都度都度推論したいわけではなく後から柔軟にクエリーしたい。そのためグラフデータベースがあっているのだ。

■Deep Learningは実用段階に
最後は、AI05のセッションで行われた「Deep Learningは実用段階に。PoCを乗り越えてビジネスで使われるためのノウハウを、AI搭載自動ごみ処理クレーンなどの事例を中心に紹介」だ。
ここでは、エンジニアが機械学習に取り組むときにどんなスキルがあればいいのか、プロジェクトを推進するのにどういうスキルがあればいいのかというのを分類して紹介している。

表の左側は、エンジニアに必要なスキルだ。Pythonのコードが読めてオープンソースのコードを学習・実行するのは、簡単である。そこから先でプログラマーが行わなければいけないのが、前処理と後処理をどうするかとハイパーパラメーターをあてがうところまでだ。
「Azure Machine Learning」に入っている「Automated ML」の機能を使うことで、誰もがある程度のハイパーパラメーターのチューニングを行うことができるところまで来ている。
その上で、アルゴリズムの改良やアルゴリズムの創造については、リサーチャーが行う。ちなみに、ハイパーパラメーターの設定ができるのは、半年前まではリサーチャーだけだった。その状況が変わってきているのである。
ディープラーニングは、PoCばかりやっていて先に進まないものが沢山ある。それは、顧客のビジネスの問題を解決できるスキルを持つ人が、プロジェクトの中にいないケースがあるからだ。
そのため、元々のビジネススキルに加えて、仕様を決め、他で真似ができない実用的なソリューションを作れるかけ算が非常に大事なのである。
今圧倒的に不足しているのは、機械学習と普通のシステム開発の両方ができるPMだ。そのため、このかけ算ができる人の人材育成がホットになっているという。
Photo&Words 高島おしゃむ
コンピュータホビー雑誌「ログイン」の編集者を経て、1999年よりフリーに。
雑誌の執筆や、ドリームキャスト用のポータルサイト「イサオ マガジン トゥデイ」の
企画・運用等に携わる。
その後、ドワンゴでモバイルサイトの企画・運営等を経て、2014年より再びフリーで活動中。